 基础数据类型
基础数据类型
# 序.数据类型概述
使用编程语言进行编程时,需要用到各种变量来存储各种信息。变量保留的是它所存储的值的内存位置。这意味着,当创建一个变量时,就会在内存中保留一些空间。
您可能需要存储各种数据类型(比如字符型、字符串、整型、浮点数、布尔型等)的信息,操作系统会根据变量的数据类型,来分配内存和决定在保留内存中存储什么。
所有在电脑中,基于数字电子学的底层资料,都是以比特 (opens new window)(0 或 1)表示。其中数据的最小的定址单位,称为字节 (opens new window)(通常是八比特 (opens new window),以八个比特为一组)。机器代码 (opens new window)指令处理的单位,称作字长 (opens new window)(至 2007 年止,一般为 32 或 64 比特)大部分对字长的指令解译,主要以二进制 (opens new window)为主。
| 类型 | 位 | 范围 |
|---|---|---|
| char | 1 个字节 | -128 到 127 或者 0 到 255 |
| unsigned char | 1 个字节 | 0 到 255 |
| signed char | 1 个字节 | -128 到 127 |
| int | 4 个字节 | -2147483648 到 2147483647 |
| unsigned int | 4 个字节 | 0 到 4294967295 |
| signed int | 4 个字节 | -2147483648 到 2147483647 |
# 一.字符串(string)
# 0.字符串运用的场景

思考:
当打来浏览器登录某些网站的时候,需要输入密码,浏览器把密码传送到服务器后,服务器会对密码进行验证,其验证过程是把之前保存的密码与本次传递过去的密码进行对比,如果相等,那么就认为密码正确,否则就认为不对;服务器既然想要存储这些密码可以用数据库(比如MySQL),当然为了简单起见,咱们可以先找个变量把密码存储起来即可;那么怎样存储带有字母的密码呢?
答:
针对这种有顺序的字符(文字、符号),使用“字符串”这种数据格式
*python中的字符串(数据类型),实际上是一种序列(sequence):序列就是计算机中的一种数据结构,在序列中可以存储一组有序的数据,序列中的每一个数据都会有一个对应的序号。数据结构和数据类型的关系,就像是“数学学课” 对 “高等数学”。
*在python中使用type()函数可以查看一个变量的数据类型
# 1.1字符串的赋值
# 1.1.1直接赋值
使用'',"",''' '''(单、双、三引号)和“=”赋值符号,进行字符串赋值
示例:
- 一对引号字符串(单引号,双引号)
name1 = 'Tom'
name2 = "Rose"
2
- 三引号字符串(三个单引号和三对双引号)
name1 = '''Tom'''
name2 = """Rose"""
a = '''
i am Tom,
nice to meet you
'''
b = """
i am Rose,
nice to meet you,too
"""
2
3
4
5
6
7
8
9
10
注意:三引号形式的字符串支持换行
思考:如何创建一个字符串 i'm Tom?
a = "i'm Tom"
print(a)
# 特别注意,这种时候需要转义,反斜杠
b = 'i\'m Tom'
print(b)
2
3
4
5
转义符:通常有两种功能:
1.编码一个和语法冲突的字符,如上边的例子:b = 'i'm Tom'使用转义\取消了'(单引号)的特殊含义
2.第二种功能,也叫字符引用,用于表示无法在当前上下文中被键盘录入的字符(如字符串中的回车符 (opens new window))
import time
for i in range(10):
print("\r离程序退出还剩%s秒" % (9-i), end="")
time.sleep(1)
2
3
4
# 1.1.2通过input()方法
# 1.1.2 字符串输入
在python中,使用input()接收用户输入。
- 代码
username = input('请输入用户名:')
print(type(username))
print(f"您输入的名字是{username}")
password = input('请输入密码:')
print(f'您输入的密码是{password}')
print(type(password))
2
3
4
5
6
# 1.2字符串拼接
每一个字符串,可以代表一段话、或者一个词组。例如:
agreement = 'http://'
ip = '121.42.15.146:9090'
url = '/mtx/'
如果想让这三个字符串,拼接成一个完整的地址。我能怎么做?
这里就要用到字符串拼接
方式1:使用加号。要求:各个变量或者元素必须是字符串类型
var1 = '字符串'
var2 = str(1)
print(var1 + var2)
print(type(var1 + var2))
2
3
4
方式2:使用join关键字,范例:
分隔符.join(要连接的变量)
# []是列表
# var=['我是','一个','列表']
# # # 单纯连接
# print(type(var))
# var=''.join(var)
# print(type(var))
# print(var)
另一种形式
# s = '2'
# s1 ='o'
# v =s,s1
# print(''.join(v))
2
3
4
5
6
7
8
9
10
11
12
13
经典误区:
print打印时使用,(逗号)不是字符串合并
print('你','好')
方式3:
使用f'' *需要python解释器是3.6之后的版本
var = '字符串'
name = f'我是{字符串}'
print(type(name))
2
3
4
5
# 1.3基于“序列”的特性
序列(sequence):序列就是计算机中的一种数据结构,在序列中可以存储一组有序的数据
序列中的每一个数据都会有一个对应的序号,这个序号我们成为索引(index)
索引是从0开始的整数
序列分为可变、不可变
不可变类型(数字,字符串,元组,不可变集合):不支持原址(内存地址)修改
举个例子:
*id()是用来查看内存地址的方法
v = '我是一个字符串'
print (id(v))
v = '我变了'
print (id(v))
2
3
4
5
# 1.3.1下标
'下标' 也就是'索引',就是编号。比如火车座位号,座位号的作用:按照编号快速找到对应的座位。
同理,下标的作用就是通过下标快速找到对应的数据

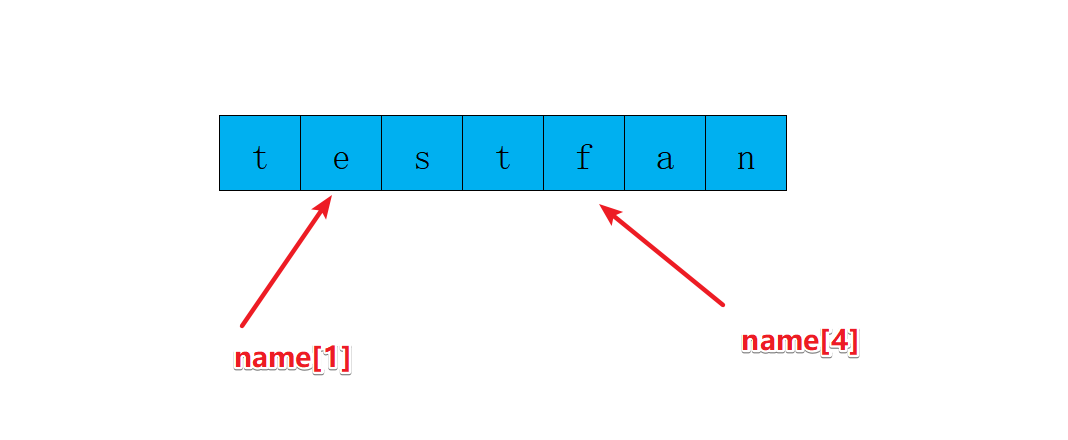
需求:字符串 name = 'testfan',取到不同下标对应的数据
# 取到不同下标对应的数据
name = 'testfan'
print(name[0])
print(name[1])
print(name[2])
#下标也可以写负数
print(name[-1])
print(name[-2])
2
3
4
5
6
7
8
*下标从0开始
# 1.3.2切片
切片是指对操作的对象截取其中一部分的操作,字符串,列表,元组都支持切片
语法
序列[开始位置下标:结束位置下标:步长]
注意:
选取的区间属于左闭右开型,即从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身),
如果不写步长默认是1.
步长是控制方向的,正数从左往右取,负数是从右到左取我们以字符串为例讲解
name = 'testfan'
print(name[2:5:1]) # 下标2到5,步长是1
print(name[2:5]) # 默认步长是1
print(name[:5]) # 不写起始,则认为是从头开始
print(name[2:5:2]) # 步长为2就后面元素的索引-前面的索引=步长
print(name[::]) # testfan
print(name[:]) # testfan
print(name[-5:-1]) # 倒叙截取,从-5个字符
print(name[-5:])
print(name[:-1])
print(name[::-1])
print(name[-3:])
print(name[2:-3])
2
3
4
5
6
7
8
9
10
11
12
13
# 小结:
1.[:]提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串
2.[start:]从start提取到结尾
3.[:end]从开头提取到end-1
4.[start:end]从start提取到end-1
5.start🔚step]从start提取到end-1,每step个字符提取一个
6.[::-1]逆序
# 1.3.3遍历字符串
python中的for循环,可以自动遍历字符串序列的每一个元素
for i in var:
if i=='一':
print('特殊处理')
print(i)
2
3
4
# 1.3.4字符串方法
字符串的常用操作方法有查找,修改和判断三大类.
我们在这先提出最必须背下来的几个方法:find()、replace()、split()
*思考一下,想要使用这里的方法,例如find(),有什么要求?
- find():检测某个字符串是否在某个字符串中,如果在,就返回子串开始位置的下标,否则,返回-1
1.语法
字符串序列.find(子串,开始位置下标,结束位置下标)
注意:开始和结束位置下标可以省略,表示在整个字符串序列当中查找
2.快速体验
str= 'hello world and testfan and yaoyao' #12
print(str.find('and')) # 返回的是字串在字符串当中的开始位置的索引
print(str.find('and',15,-1)) #24
print(str.find('ands')) # -1
2
3
4
replace():替换
1.语法
字符串序列.replace(旧子串,新子串,替换次数)1注意:替换次数如果超出子串出现的次数,则替换次数为该子串出现的次数
2.快速体验
str = 'hello world and testfan and yaoyao' # 1.replace # 结果:hello world and testfan and yaoyao print(str) # 字符串是不可变类型,所以不会改变原来数据的结构 # 结果:hello world and testfan and python print(str.replace('yaoyao','python')) # 结果:hello world 2 testfan 2 yaoyao print(str.replace('and','2')) # 默认是更改所有的 # 结果:hello world 2 testfan and yaoyao print(str.replace('and','2',1)) # 结果:hello world 2 testfan 2 yaoyao print(str.replace('and','2',3))1
2
3
4
5
6
7
8
9
10
11
12
13注意:数据按照是否能直接修改分为可变类型和 不可变类型两种。字符串类型的数据修改的时候不能改变原有字符串,属于不能直接修改数据的类型即是不可变类型。
split(): 按照指定字符分隔字符串
1.语法
字符串序列.split(分割字符,num)
注意:num表示的是分隔字符出现的次数,即将来返回数据个数为num+1
2.快速体验
# 结果:['hello', 'world', 'and', 'testfan', 'and', 'yaoyao']
print(str.split(' ')) # 经过split()分隔之后就是一个列表
# 结果:['hello', 'world', 'and testfan and yaoyao']
print(str.split(' ', 2))
# 结果: ['hello world ', ' testfan ', ' yaoyao']
print(str.split('and')) # 如果分隔符是字符串序列的一个子串,那么就会丢失
2
3
4
5
6
注意: 如果分割字符是原有字符串中的子串,分割后则丢失该子串
# 1.3.4.1查找
- index(): 检测某个子串是否包含在这个字符串中,如果在则返回这个子串开始位置的索引位置,不在则会报异常
1.语法
字符串序列.index(子串,开始位置下标,结束位置下标)
注意:开始和结束位置下标可以省略,表示在整个字符串序列中查找
2.快速体验
str= 'hello world and testfan and yaoyao'
print(str.index('and')) # 返回的是字串在字符串当中的开始位置的索引 12
print(str.index('and',15,-1)) #24
print(str.index('ands')) # 报错
2
3
4
所谓字符串查找方法即是查找子串在字符串中的位置或出现的次数
rfind(): 和find()功能相同,但查找方向为右侧开始
rindex():和index()功能相同,但查找方向为右侧开始
count():返回某个子串在字符串中出现的次数
1.语法
字符串序列.count(子串,开始位置下标,结束下标)
注意:开始和结束位置下标可以省略,表示在整个字符串中查找
2.快速体验
str= 'hello world and testfan and yaoyao'
print(str.count('and')) # 2
print(str.count('and',15,-1)) # 1
print(str.count('ands')) # 0
2
3
4
# 1.3.4.2 修改
所谓修改字符串,指的就是通过函数的形式修改字符串中的数据
- capitalize(): 将字符串第一个字符串转换成大写
str = 'hello world and testfan and yaoyao'
# 结果是Hello world and testfan and yaoyao
print(str.capitalize())
2
3
注意:capitalize()函数转换后,只字符串第一个字符大写,其他的字符全都小写
- title() :将字符串每个单词首字母转换成大写
str = 'hello world and testfan and yaoyao'
#结果:Hello World And Testfan And Yaoyao
print(str.title())
2
3
- lower(): 将字符串中大写转小写
str1=str.title()
print(str1)
print(str.lower())
2
3
- upper():将字符串中小写转大写
str = 'hello world and testfan and yaoyao'
# 结果:HELLO WORLD AND TESTFAN AND YAOYAO
print(str.upper())
2
3
- lstrip():删除字符串左侧空白字符
str = ' hello world and testfan and yaoyao'
print(str)
print(str.lstrip())
2
3
执行结果:

- rstirp():删除字符串右侧空白字符

- strip():删除字符串两侧空白字符

- ljust():返回一个原字符串左对齐,并使用指定字符(默认空格)填充至对应长度的新字符串
语法
字符串序列.ljust(长度,填充字符)1
2.输出效果

- rjust():返回一个原字符串右对齐,并使用指定字符(默认空格)填充至对应长度的新字符串,语法和ljust()相同
- center():返回一个原字符居中对齐,并使用指定字符(默认空格)填充对应长度的字符串,语法和ljust()相同

# 1.3.4.3 判断
所谓判断即是判断真假,返回的结果是布尔型数据类型:True 或 False
- startswith():检查字符串是否是以指定子串开头,是则返回True,否则返回False。如果设置开始和结束位置下标,则在指定范围内检查
1.语法
字符串序列.startswith(子串,开始位置下标,结束位置下标)
2.快速体验
str1 = 'helloworld11111'
print(str1.startswith('hell')) # True
print(str1.startswith('hello',5,-1)) #False
2
3
endswith(): 检查字符串是否是以指定子串结尾,是则返回True,否则返回False。
如果设置开始和结束位置下标,则在指定范围内检查
1.语法
字符串序列.endswith(子串,开始位置下标,结束位置下标)12.快速体验
str1 = 'helloworld11111' print(str1.endswith('11')) # True print(str1.endswith('11',0,7)) # False1
2
3isalpha():如果字符串至少有一个字符并且所有的字符都是字母则返回True,否则返回False
str1='hello'
str2='hello111'
str3=''
print(str1.isalpha()) # True
print(str2.isalpha()) # False
print(str3.isalpha()) # False
2
3
4
5
6
- isdigit():如果字符串只包含数字则返回True,否则返回False
str1 = '1234'
str2 = 'hello 777'
print(str1.isdigit()) # True
print(str2.isdigit()) # False
2
3
4
- isalnum():如果字符串中至少有一个字符并且所有的字符是字母或者数字则返回True,否则返回False
str1 ='aaa123'
str2 ='aaa-'
print(str1.isalnum()) # True
print(str2.isalnum()) # False
2
3
4
- isspace(): 如果字符串中只包含空白,则返回True,否则返回False
str1 = ' '
str2 = ' hello'
print(str1.isspace()) # True
print(str2.isspace()) # False
2
3
4
# 面试题
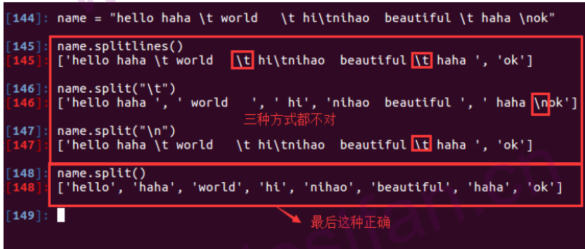
给定一个字符串aStr字符串中有空格\n和\t等,要求处理后返回字符串里面不能有\n或者\t和空格。
name = "hello haha\t world\t hi\tnihao beautiful\t haha\nok
思路:
# 二.列表
# 0.列表的用途
思考:前面学习的字符串可以用来存储一串信息,那么想一想,怎样存储咱们班所有同学的名字呢? 定义100个变量,每个变量存放一个学生的姓名可行吗?有更好的办法吗?
答:使用“列表”
# 1. 列表的基本规则
1.列表使用[]来表示
2.初始化列表:
list = []
3.列表可以一次性存储多个数据
[数据1,数据2,数据3,.....]
4.列表中的每一项,都能是不同的数据类型。(包括列表)
# 范例:
#列表的元素多种多样(指类型)
test_list = [1,'a',[1,2],{"name":"刘备"},{2,3},(1,2,"李四")]
#列表的输出
names_list = ['刘备','曹操','孙权']
print(names_list[0])
print(names_list[1])
print(names_list[2])
print(names_list)
2
3
4
5
6
7
8
列表的作用是一次性存储多个数据,程序员可以对这些数据进行的操作有:增删改查
# 2.列表的常用操作
# 2.1查找
# 2.1.1下标
name_list=['tom','lily','rose']
print(name_list[0]) # tom
print(name_list[1]) #lily
print(name_list[2]) # rose
2
3
4
# 2.1.2函数(方法)
- index(): 返回指定数据所在位置的下标
1.语法
列表序列.index(数据,开始位置的下标,结束位置的下标)
2.快速体验
name_list = ['tom','lily','rose']
print(name_list.index('tom')) # 0
2
注意:如果查找的数据不存在则报错
- count():统计指定数据在当前列表中出现的次数
name_list=['tom','lily','rose']
print(name_list.count('tom')) # 1
2
len():可以获取列表的长度,即列表中数据的个数
name_list=['tom','lily','rose'] print(len(name_list)) # 31
2
# 2.1.3 判断是否存在
- in:判断指定的数据在某个列表序列,如果在返回True,否则返回False
name_list=['tom','lily','rose']
print('lily'in name_list) #True
print('yao' in name_list) #False
2
3
not in :判断指定的数据不在某个列表序列,如果不在返回True,否则返回False
name_list=['tom','lily','rose'] print('tom' not in name_list) # False print('yaoyao' not in name_list) #True1
2
3体验案例
需求:查找用户输入的名字是否存在
name_list=['tom','lily','rose']
name = input('请输入你要搜索的名字:')
if name in name_list:
print(f'您搜索的{name}存在')
else:
print(f'您搜索的{name}不存在')
2
3
4
5
6
# 2.2增加
作用:增加指定数据到列表中
- append():列表尾部追加数据
1.语法
列表序列.append(数据)
2.体验
name=['tom','lily','rose']
name.append('xiaoming')
print(name)
2
3
执行结果:

列表追加数据的时候,直接在原列表里面追加了指定数据,即修改了原列表,故列表为可变类型数据
3.注意点
如果append()追加的数据是一个序列,则追加整个序列到列表,整体新增一个元素。
name_list = ['tom','lily','rose']
name_list.append(['xiaoming','xiaohong'])
# 结果:['tom', 'lily', 'rose', ['xiaoming', 'xiaohong']]
print(name_list)
2
3
4
- insert(): 指定位置新增数据
1.语法
列表序列.insert(位置下标,数据)
2.快速体验
name_list = ['tom','lily','rose']
name_list.insert(0,'yaoyao')
# 结果:['yaoyao', 'tom', 'lily', 'rose']
print(name_list)
2
3
4
- extent(): 列表结尾追加数据,如果数据是一个序列,则将这个序列的数据逐一加入列表中
1.语法
列表序列.extend(数据)
2.快速体验
2.1单个数据(可迭代的)
name_list = ['tom','lily','rose']
name_list.extend('abc')
#结果:['tom', 'lily', 'rose', 'a', 'b', 'c']
print(name_list)
2
3
4
2.2序列数据
name_list = ['tom','lily','rose']
name_list.extend(['a','b','c'])
#结果:['tom', 'lily', 'rose', 'a', 'b', 'c']
print(name_list)
2
3
4
# 2.3删除
- del
1.语法
del 目标
2.快速体验
2.1删除列表
name_list = ['tom','lily','rose']
del name_list
#结果:NameError: name 'name_list' is not defined
print(name_list)
2
3
4
2.2删除指定数据
name_list = ['tom','lily','rose']
del name_list[0]
# ['lily', 'rose']
print(name_list)
2
3
4
- remove()
- pop():删除指定下标的数据(默认为最后一个),并返回该数据
1.语法
列表.pop(index)
2.快速体验
name_list = ['tom','lily','rose']
del_name = name_list.pop(0) # 返回的是被删除的元素
#结果是tom
print(del_name)
#结果是['lily', 'rose']
print(name_list)
# 不加索引,默认删除最后一个元素
name_list.pop()
# 结果是['lily']
print(name_list)
2
3
4
5
6
7
8
9
10
- clear():清空列表
name_list = ['tom','lily','rose']
name_list.clear() #清除列表里面的所有元素
# 结果是[]
print(name_list)
2
3
4
# 2.4修改
- 修改指定下标数据
name_list = ['tom','lily','rose']
name_list[0]='yaoyao'
#['yaoyao', 'lily', 'rose']
print(name_list)
2
3
4
逆转:reverse()
name_list=['tom','lily','rose'] name_list.reverse() # ['rose', 'lily', 'tom'] print(name_list)1
2
3
4排序:sort()
1.语法
列表.sort(key=None,reverse=False)
注意:reverse表示排序规则,reverse=True 降序,reverse=False 升序(默认)
2.快速体验
name_list=[1,7,3,2,8]
name_list.sort()
# [1, 2, 3, 7, 8]
print(name_list)
2
3
4
# 2.5复制
函数:copy()
name_list=['tom','lily','rose']
new_list = name_list.copy()
# 结果是['tom', 'lily', 'rose']
print(new_list)
2
3
4
# 3. 列表的循环遍历
需求:依次打印列表中的各个数据
# 3.1 while
- 代码
name_list=['tom','lily','rose']
n=0
while n<len(name_list):
print(name_list[n])
n += 1
2
3
4
5
- 执行结果:

# 3.2 for
- 代码
name_list=['tom','lily','rose']
for i in name_list:
print(i)
2
3
# 4. 列表嵌套
所谓列表嵌套指的是一个列表里面包含了其他的子列表
应用场景:要存储高三三个班级的学生名字,每个班级的学生名字为一个列表
name_list = [['xiaoming','xiaohong','xiaoli'],['tom','lily','rose'],['小李','小杨','小张']]
思考:如何查找到数据"小李"
print(name_list[2][0])
# 5. 综合应用-随机分配办公室
需求:有三个办公室,8位老师,8位老师随机分配到3个办公室

# 三.元组
# 1.元组的应用场景
思考:如果想要存储多个数据,但是这些数据是不能修改的数据,怎么做?
答:列表?列表可以一次性存储多个数据,但是列表中的数据允许更改
num_list =[10,20,30]
num_list[0] = 100
2
一个元组可以存储多个数据,元组内的数据是不能修改的
# 2.定义元组
元组特点:定义元组使用小括号,且逗号隔开各个数据,数据可以是不同的数据类型。
# 多个数据元组
t1 = (10,20,40)
# 单个数据元组
t2 = (10,)
2
3
4
注意: 如果定义的元组只有一个数据,那么这个数据后面也要添加逗号,否则数据类型就变成了元组里面的哪个唯一的数据的数据类型
a = (1)
print(type(a)) #<class 'int'>
b = ('你好')
print(type(b)) # <class 'str'>
c = ('yaoyao',)
print(type(c)) #<class 'tuple'>
2
3
4
5
6
# 3.元组的常见操作
元组数据不支持修改,只支持查找,具体如下:
- 按照下标查找数据
tuple1 = ('aa','bb','cc','dd')
print(tuple1[0]) # aa
2
- index() 查找某个数据,如果数据存在返回对应的下标,否则报错,语法如列表,字符串的index方法相同
tuple1 = ('aa','bb','cc','dd')
print(tuple1.index('aa')) # 0
2
- count() 统计某个数据在当前元组中出现的次数
tuple1 = ('aa','bb','cc','dd')
print(tuple1.count('aa')) # 1
2
- len() 统计元组中数据的个数
tuple1 = ('aa','bb','cc','dd')
print(len(tuple1)) # 4
2
注意:元组内的直接数据如果修改则立即报错
tuple1 =('aa','bb','cc','dd')
tuple1[0]='mm' # TypeError: 'tuple' object does not support item assignment
2
但是如果元组里面有列表,修改列表里面的数据则是支持的,故自觉很重要
tuple1 = (10,20,20,['lily','lucy'],40)
tuple1[3][0]='tom'
# 结果是(10, 20, 20, ['tom', 'lucy'], 40)
print(tuple1)
2
3
4
# 四.字典
# 目标
- 字典的应用场景
- 创建字典的语法
- 字典常见的操作
- 字典的循环遍历
# 1. 字典的应用场景
思考1:如果有多个数据,例如:tom,男,20,那么如何快速存储呢?
答:列表
list1 = ['tom','男',20]
思考2:如何查找到数据"tom"?
答:查找到下标为0 的数据即可
list1[0]
思考3:如果将来数据顺序发生变化,那么还能用下标0去获取'tom'吗?
list1 = ['男',20,’tom]
答:不能,数据‘tom’此时的下标为2
思考4:数据顺序发生变化,每个数据的下标也会随之变化,如何保证数据顺序变化前后能使用统一的标准查找数据呢?
答: 字典,字典里面的数据是以键值对形式出现,字典数据跟数据顺序没有关系,即字典不支持下标,后期无论数据如何变化,只需要按照对应的键的名字查找数据即可
# 2. 创建字典的语法
字典的特点
- 符号用大括号
- 里面的数据以键值对形式出现
- 各个键值对之间用逗号隔开
#有数据的字典
dict1 = {'name':'tom','age':20,'gender':'男'}
#空字典
dict2 = {}
dict3 = dict()
2
3
4
5
注意:一般称冒号前面的为键(key),简称k,冒号后面的为值(value),简称v
# 3. 字典常见操作
# 3.1 增
写法:字典序列[key]=值
注意:如果key存在则修改这个key对应的值,如果key不存在则新增此键值对
dict1 ={'name':'tom','age':20,'gender':'男'}
# 结果是{'name': 'lily', 'age': 20, 'gender': '男'}
dict1['name']='lily'
print(dict1)
dict1['id']='001'
# 结果是{'name': 'lily', 'age': 20, 'gender': '男'}
print(dict1)
2
3
4
5
6
7
字典为可变类型
# 3.2删
- del()/del: 删除字典或删除字典中指定键值对
dict1 ={'name':'tom','age':20,'gender':'男'}
del dict1['name']
print(dict1) #{'age': 20, 'gender': '男'}
del(dict1['age'])
print(dict1) # {'gender': '男'}
del dict1
print(dict1) # 报错:字典没有被定义
2
3
4
5
6
7
- clear() 清空字典
dict1 ={'name':'tom','age':20,'gender':'男'}
dict1.clear()
print(dict1) # {}
2
3
# 3.3 改
写法:字典序列[key]=值
注意:如果key存在则修改,不存在则添加
# 3.4 查
# 3.4.1 key值查找
dict1 ={'name':'tom','age':20,'gender':'男'}
print(dict1['name']) #tom
print(dict1['id']) #报错
2
3
注意:如果当前查找的key存在,则返回对应的值,否则会报错。
# 3.4.2 get()
- 语法
dict.get(key,默认值)
注意:如果当前不存在这个key,则会返回第二个参数自定义的默认值,如果没有第二个参数,则返回默认的None
快速体验
dict1 ={'name':'tom','age':20,'gender':'男'}
print(dict1.get('name')) # tom
print(dict1.get('id', '不存在')) # 不存在
2
3
# 3.4.3 keys()
dict1 ={'name':'tom','age':20,'gender':'男'}
print(dict1.keys()) # dict_keys(['name', 'age', 'gender'])
2
# 3.4.4 values()
dict1 ={'name':'tom','age':20,'gender':'男'}
print(dict1.values()) # dict_values(['tom', 20, '男'])
2
# 3.4.5 items()
dict1 ={'name':'tom','age':20,'gender':'男'}
print(dict1.items()) # dict_items([('name', 'tom'), ('age', 20), ('gender', '男')])
2
# 4. 字典的循环遍历
# 4.1 遍历字典的key
dict = {'name':'tom','age':20,'gender':'男'}
for k in dict.keys():
print(k)
2
3
执行结果是

# 4.2遍历字典的value
dict = {'name':'tom','age':20,'gender':'男'}
for v in dict.values():
print(v)
2
3
执行结果是

# 4.2遍历字典的元素
dict = {'name':'tom','age':20,'gender':'男'}
for items in dict.iitems()
print(items)
2
3
执行结果是

# 4.3遍历字典的键值对
dict = {'name':'tom','age':20,'gender':'男'}
for k,v in dict.items():
print(k,v)
2
3
执行结果

[TOC]