 语音与多模态接口回归
语音与多模态接口回归
# 语音与多模态接口回归
公开版案例说明:以下内容已做泛化处理,不包含真实模型名、环境名、计费表结构或任何内部接口信息。
# 我解决了什么
- 将一轮接口回归从 1 天缩短到约 2 小时
- 覆盖功能、异常、边界和结果核对等核心场景
- 让 Agent 根据任务特点选择合适执行方式,而不是固定只跑一种工具
# 典型难点
这类接口回归通常会同时面对几个问题:
- 同一能力存在多入口或多种调用方式
- 正向、异常、边界场景很多,人工整理容易失控
- 仅看接口返回不够,还需要检查落库和关联页面,关联参数是否正确
- 不同任务对速度、覆盖率和证据粒度要求不同
# 我怎么做
我把回归拆成可复用的执行路径:
- 使用预设 case 与样本资源建立回归任务
- 根据任务目标选择
curl、pytest、scenario runner 或Locust - 执行功能、异常、边界和结果核对
- 自动汇总为结构化报告,保留关键证据
这种方式的核心不是“全自动”,而是让 Agent 负责高重复度执行,人来把关关键判断和结论。
# 可公开量化结果
| 指标 | 结果 |
|---|---|
| 单轮回归耗时 | 约 1 天 -> 约 2 小时 |
| 覆盖内容 | 功能、异常、边界、结果核对 |
| 执行方式 | curl / pytest / runner / Locust |
| 输出产物 | 结构化报告、聚合结论、关键证据 |
# 结果怎么呈现
我会把结果统一整理成几个层次:
- 单场景执行结果
- 汇总统计,如通过率和异常分布
- 面向沟通的 HTML 报告
- 面向复盘的 JSON/日志/证据
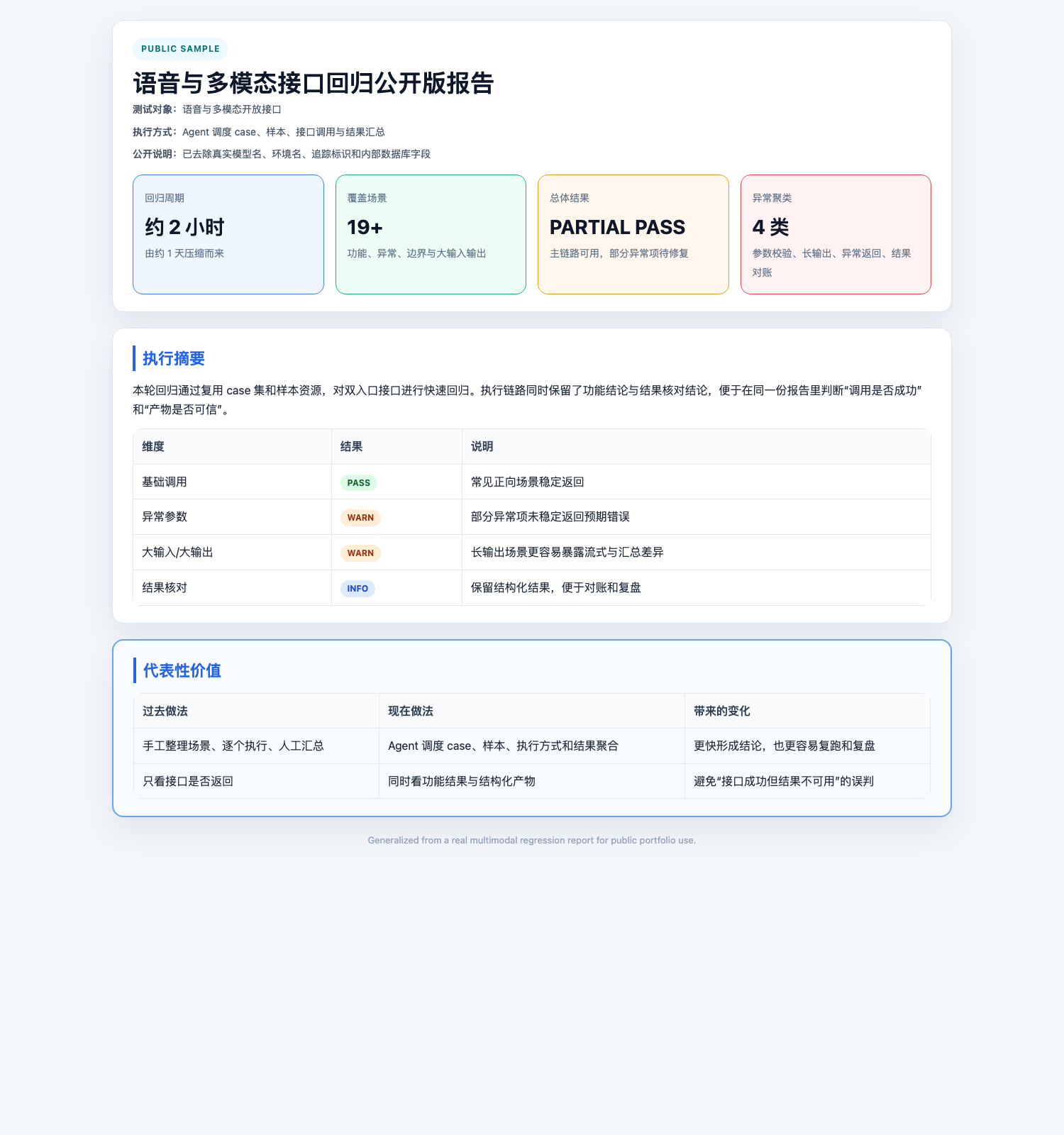
上图是基于真实回归报告整理的公开版摘要截图,保留了执行结果、覆盖范围和异常状态的表达方式,同时去除了真实模型名、环境名和内部标识。
# 我的价值
这个案例体现的是 AI 测试的理解不是停留在“让模型帮我写用例”,而是把测试对象、执行方式、结果表达和证据沉淀一起设计出来,让复杂回归在速度和可控性之间取得平衡。