 httprunner3.x的简介
httprunner3.x的简介
# httprunner3.x的简介
# 简介:
HttpRunner是一款面向HTTP(s)协议的通用测试框架,只需编写维护一份 测试脚本,即可实现自动化测试、性能测试、持续集成等多种测试需求。
# 参考资料:
github地址:https://github.com/HttpRunner/HttpRunner 3.x用户手册:https://docs.httprunner.org/user/gen_tests/
# 框架的优点
- 继承 Requests 的全部特性,轻松实现 HTTP(S) 的各种测试需求
- 测试用例与代码分离,采用YAML/JSON/Pytest的形式描述测试场景,保障测试用例具备可维护性
- 测试用例支持分层机制,充分实现测试用例的复用
- 测试用例支持参数化和数据驱动机制
- 使用 skip 机制实现对测试用例的分组执行控制
- 测试请求支持完善的hook机制
- 支持热加载机制,在文本测试用例中轻松实现复杂的动态计算逻辑
- 基于 HAR 实现接口录制和用例生成功能(har2case)
- 结合 Locust 框架,无需额外的工作即可实现分布式性能测试
- 执行方式采用 CLI 调用,可与 Jenkins 等持续集成工具完美结合
- 测试结果统计报告简洁清晰,附带详尽统计信息和日志记录
- 具有可扩展性,便于扩展实现 Web 平台化(HttpRunnerManager)
# 安装及创建项目
pip install httprunner==3.1.4
可以通过以下命令验证是否成功
hrun -V
首先cd到你想要创建项目的目录下面,然后通过下面的命令行创建项目
httprunner startproject 项目名称
# 录制接口请求
如果不知道如何去写单独api的自动化脚本,那么可以通过录制功能去实现,首先下载
pip install har2case
然后通过fiddler去抓取对应的接口,选中对应的接口,然后导出成HTTPArchive v1.2,选中这个,然后导出保存为demo.har,再用以下命令转换成测试脚本
默认生成pytest测试脚本
har2case demo.har
以下命令可以生成yml文件
har2case -2y demo.har
运行测试用例用如下命令,即
hrun demo.json/demo.yml
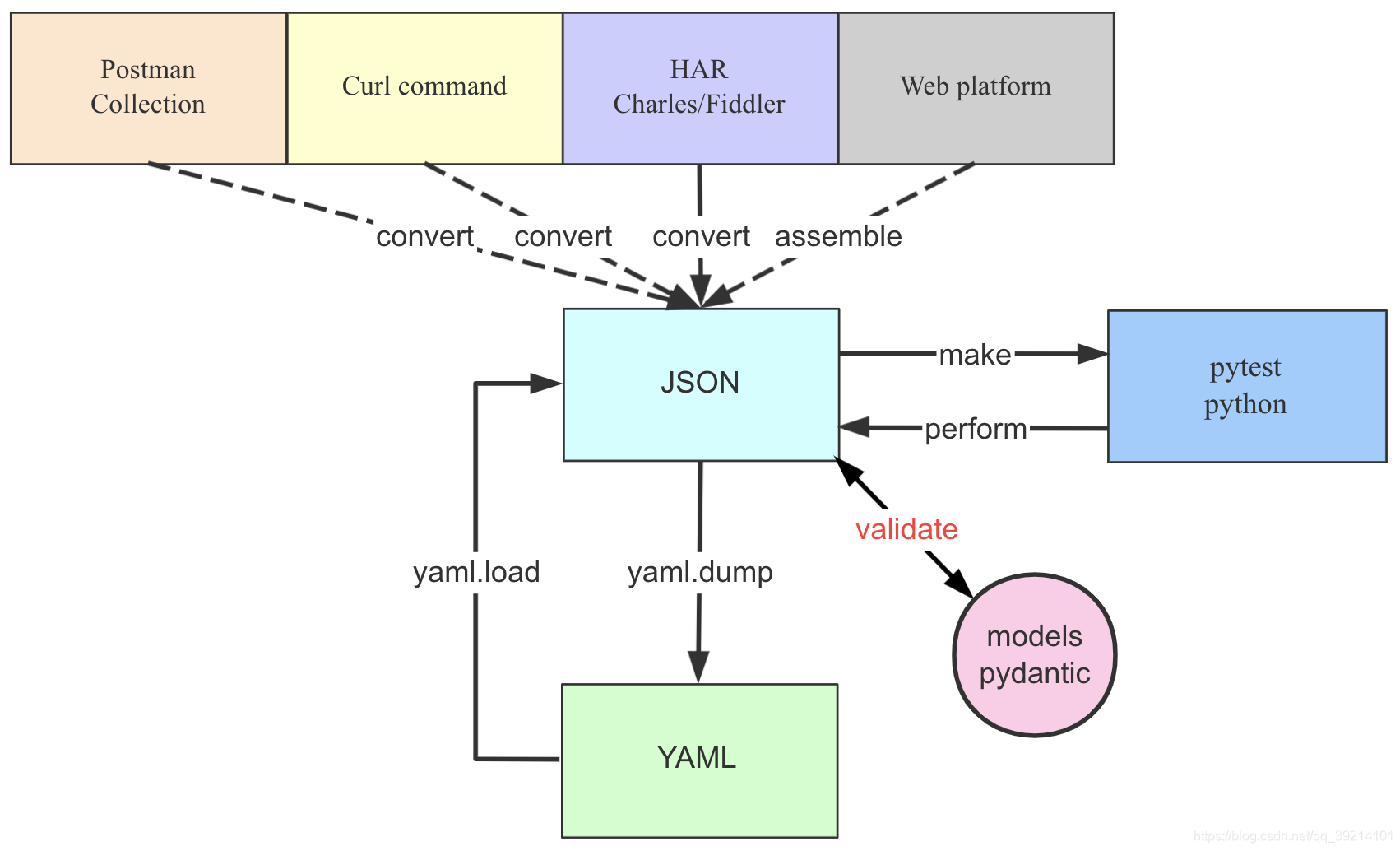
*httprunner中的三种case形式
HttpRunner v3.x支持三种测试用例格式pytest,YAML和JSON。强烈建议以pytest格式而不是以前的YAML/JSON格式编写和维护测试用例。
相互转换格式关系如下图所示:
# 执行方式
# 使用hrun命令:
hrun interfaceDemo
# 使用pytest命令:
pytest interfaceDemo
# pytest脚本在编译器中执行:
from httprunner import HttpRunner, Config, Step, RunRequest, RunTestCase
class TestCaseString(HttpRunner):...
if __name__ == "__main__":
TestCaseString().test_start()
2
3
4
5
6
# 修改自动生成的脚本
# 特性:
- 每个testcase都是HttpRunner的子类
- 必须有两个类属性:config和teststeps。
- 单个teststeps列表中的单个Step内部通过链式调用(RunRequest().get().with_params().with_header().with_cookies().validate().assert_equal())
# 知识点:
- config:配置测试用例级设置,包括基础url、验证、变量、导出。
- teststeps:teststep的列表(list[Step]),每个步骤对应于一个API请求,也可以调用另一个testcase。此外,还支持variables/extract/validate/hooks机制来创建极其复杂的测试场景。
- 链调用:可以看到一个case的请求,经过了各个环节的调用,这也是httprunner 3.x版本一大亮点。现在的ide编辑器越来越强大,比如你使用pycharm的话,都不用你怎么记忆用例的格式,顺手就...(点)出来了,这或许也是官方推荐使用pytest的另一个原因吧,
# config属性能做什么?
每个测试用例都应该有一个config部分,您可以在其中配置测试用例级别的设置。
# name(必填)
指定测试用例名称。这将显示在执行日志和测试报告中。
# base_url(可选)
指定SUT的通用架构和主机部分,例如https://postman-echo.com。如果base_url指定,则teststep中的url只能设置相对路径部分。如果要在不同的SUT环境之间切换,这将特别有用。
# variables(可选)
指定测试用例的公共变量。每个测试步骤都可以引用未在步骤变量中设置的配置变量。换句话说,步骤变量比配置变量具有更高的优先级。
# verify (可选)
指定是否验证服务器的TLS证书。如果我们想记录测试用例执行的HTTP流量,这将特别有用,因为如果没有设置verify或将其设置为True,则会发生SSLError。
SSLError(SSLCertVerificationError(1,'[SSL:CERTIFICATE_VERIFY_FAILED]证书验证失败:证书链中的自签名证书(_ssl.c:1076)')
# export (可选)
指定导出的测试用例会话变量。将每个测试用例视为一个黑盒,config variables是输入部分,而config export是输出部分。特别是,当一个测试用例在另一个测试用例的步骤中被引用,并且将被提取一些会话变量以在后续测试步骤中使用时,则提取的会话变量应在配置export部分中进行配置。将测试用例的某些变量指定为全局变量。(PS:不配置export在另一个引用类中进行该累的变量调用时,直接export也是可以的,最好还是配置一下)
# teststep能做什么?
先说一下,这里分为测试步骤 和 外部case依赖两种情况
# 1.对于测试步骤而言
# RunRequest(名称)
RunRequest 在一个步骤中用于向API发出请求,并对响应进行一些提取或验证。
# .name
RunRequest 的参数用于指定测试步骤名称,该名称将显示在执行日志和测试报告中。
# .with_variables
指定测试步骤变量。每个步骤的变量都是独立的,因此,如果要在多个步骤中共享变量,则应在配置变量中定义变量。此外,步骤变量将覆盖配置变量中具有相同名称的变量。(PS:注意参数传递的格式使用**{},使用关键字参数解包的方式进行参数传递给with_variables),参数引用使用"$变量名",如果是函数引用使用"${函数名()}"
# method(url)
指定HTTP方法和SUT的URL。这些对应于method和url参数requests.request (opens new window)。
如果base_url在config中设置,则url只能设置相对路径部分。如果在Config中设置了baseurl,method中只能设置相对路径,可选参数为get/post/put/delete/等。
# .with_params
指定请求网址的查询字符串。这对应于的params参数requests.request (opens new window)。
# .with_headers
为请求指定HTTP标头。这对应于的headers参数requests.request (opens new window)。
# .with_cookies
指定HTTP请求cookie。这对应于的cookies参数requests.request (opens new window)。
# .with_data
指定HTTP请求正文。这对应于的data参数requests.request (opens new window)。
# .with_json
在json中指定HTTP请求正文。这对应于的json参数requests.request (opens new window)。
# extract(数据提取)
.WITH_JMESPATH
使用jmespath (opens new window)提取JSON响应主体。
with_jmespath(jmes_path:文字,var_name:文字)
- jmes_path:jmespath表达式,有关更多详细信息,请参考JMESPath教程 (opens new window)
- var_name:存储提取值的变量名,可以在后续测试步骤中引用它
# validate
.ASSERT_XXX
使用jmespath (opens new window)提取JSON响应主体并使用期望值 (opens new window)进行验证。
assert_XXX(jmes_path:文本,期望值:任何,消息:文本=“”)
- jmes_path:jmespath表达式,有关更多详细信息,请参考JMESPath教程 (opens new window)
- Expected_value:指定的期望值,变量或函数引用也可以在此处使用
- 消息(可选):用于指示断言错误的原因
# 2.引用其他case的情况
# RunTestCase(名称)
RunTestCase 在一个步骤中用于引用另一个测试用例调用。
# .name
RunTestCase 的参数用于指定测试步骤名称,该名称将显示在执行日志和测试报告中。
# .with_variables
指定测试步骤变量。每个步骤的变量都是独立的,因此,如果要在多个步骤中共享变量,则应在配置变量中定义变量。此外,步骤变量将覆盖配置变量中具有相同名称的变量。
# .call
指定引用的测试用例类。你在引用另一个测试用例的step中的参数时,需要先指定引用的测试用例类
# .export
指定会话变量名称以从引用的测试用例中导出。导出的变量可以通过后续测试步骤step进行引用。导出的是step中的jmespath提取的变量,export之后,这个变量是全局变量,但是不能再confg中进行设置,因为测试类的引用是在step中进行的,而类的初始化是先初始化config,然后初始化teststeps,所以参数的传递在step之间
# 什么是脚手架
在软件开发上(当然也包括前端开发)的脚手架指的就是:有人帮你把这个开发过程中要用到的工具、环境都配置好了,你就可以方便地直接开始做开发,专注你的业务,而不用再花时间去配置这个开发环境,这个开发环境就是脚手架。
# 项目架构
各个目录代表的含义:
- debugtalk.py 放置在项目根目录下(借鉴了pytest的conftest文件的设计)
- .env 放置在项目根目录下,可以用于存放一些环境变量
- reports 文件夹:存储 HTML 测试报告
- testcases 用于存放测试用例
- har 可以存放录制导出的.har文件
- .gitignore 设置上传到git时需要忽略那些文件信息
# 参数化
参数化有三种方式,具体内容如下:
第一种,使用httprunner改造过的pytest参数化,通过parameters这个字段去引用
@pytest.mark.parametrize(
"param",
Parameters(
{
"first": ["first", "second"],
"second":['random string','string number']
}
),
)
2
3
4
5
6
7
8
9
第二种,通过csv文件httprunner可以读取同目录下的csv文件
#代码中如此书写
@pytest.mark.parametrize("param", Parameters(
{"username-password":"${parameterize(data.csv)}"}
))
#使用csv文件进行参数化的时候,Parameters的键里每一个-代表一个参数分割。例如username 和 password是两个参数
# 相应的,csv文件中的列名应该和参数名一致
2
3
4
5
6
7
数据文件
username,password
name1,1212
name2,4545
2
3
第三种,通过debugtalk.py进行构建
代码中这样调用:
@pytest.mark.parametrize("param", Parameters(
{"username": "${get_username()}"}
))
#以上方式是使用debugtalk中的方法返回值
2
3
4
在debugtalk里面定义:
# @File: debugtalk.py
# ---
def get_username():
return [
{"username": "111111"},
{"username": "222222"},
{"username": "333333"},
{"username": "444444"},
{"username": "555555"},
{"username": "666666"},
]
2
3
4
5
6
7
8
9
10
11
12
# 测试报告和命令行执行
3.x版本httprunner可以使用两种测试报告(本质上是用的pytest)
# 1.pytest-html和pytest普通用法一致
pytest case文件.py --html=report.html
pytest case文件.py --html=report.html --self-contained-html
2.使用allure需要安装httprunner插件
pip install httprunner[allure]
执行命令:
pytest case名称.py --alluredir ./预计存放数据的路径
allure generate 数据存放路径 -o 报告输出路径 --clean