 ASR与翻译准确性评测
ASR与翻译准确性评测
# ASR与翻译准确性评测
公开版案例说明:以下内容只展示评测方法、链路设计和报告结构,不展示任何真实样本、音频、内部接口或厂商标识。
# 0. 先对齐两个名词
为方便阅读,先把本文涉及的两个核心能力说清楚:
- ASR(Automatic Speech Recognition,自动语音识别):把一段音频转成对应语种的文本。本文涉及的 ASR 覆盖多语种,包括中文、英文、日文等。
- 翻译(Speech Translation):在 ASR 之上,把源语言语音翻译成目标语言文本。常见形式包括同传式流式输出、最终译文输出,部分场景还会附带 TTS 合成。
两者的关系可以理解为:翻译链路 ≈ ASR 转写 + 跨语言翻译。区别在于翻译必须额外保证"目标语言表达正确、语义无损",因此翻译评测比纯 ASR 评测多一层"语义诊断"。
# 1. 目标:把"感觉还不错"变成可复盘的客观评测
ASR 与实时翻译质量很容易停留在主观判断:
- 不同人对"翻得好不好"的标准不一致
- 只看几条样本,很难代表整体能力
- 只给一句"效果还行/不太行",无法指导模型或产品改进
- 没有标准数据和原始证据,下一轮复测无法对齐
目标是把语音和翻译能力变成可以批量验证、可以量化比较、可以定位问题的工程化评测,让"ASR/翻译效果如何"这个问题从主观感受变成可测量、可解释、可复盘的客观结论。
# 2. 评测覆盖的两类任务
| 任务 | 输入 | 标准答案 | 输出 | 主要关注点 |
|---|---|---|---|---|
| ASR 准确性 | 源语言音频 | 源语言人工转写 | 模型转写文本 | 转写是否准确、是否漏字错字、是否空结果 |
| 实时翻译准确性 | 源语言音频 | 目标语言参考译文 | 模型译文 / 同传结果 | 译文是否表达正确、是否漏译错译、是否有严重语义问题 |
两者的共性是:都需要标准答案、都需要批量执行、都需要自动指标 + bad case 解释。
# 3. 评测链路如何运转
完整链路可以拆为 8 个步骤:
flowchart LR
A[标准音频与参考答案] --> B[manifest 数据清单]
B --> C[task config]
C --> D[批量调用 ASR/翻译接口]
D --> E[保存原始响应与预测文本]
E --> F[CER/WER 等自动评分]
F --> G[模型辅助诊断问题类型]
G --> H[HTML 报告与改进建议]
2
3
4
5
6
7
8
# 3.1 标准数据准备
每条样本至少要包含:
- 音频文件
- 标准转写或标准译文
- 样本 ID
- 语言方向
- 数据来源或标签
整理成 manifest.jsonl,例如:
{"sample_id":"en_0001","audio_path":"audio/0001.flac","reference_text":"标准转写或标准译文","language":"en","tags":["en","benchmark","v1"]}
这一步的关键不是"能不能跑",而是"数据是否可信"。如果标准答案本身不可靠,后面的自动评分就会把数据问题误判成模型问题。
# 3.2 批量调用接口
脚本会读取 manifest 和 task config,逐条调用 ASR 或实时翻译接口,并保存:
- 原始响应事件
- 模型预测文本
- 接口状态
- session / trace 信息
- 延迟
- 错误信息
报告里的每个结论都能回到原始证据,而不是只保留一个平均分。
# 3.3 自动评分
ASR 转写任务通常先计算 CER 或 WER:
- CER:字符错误率,适合中文、日文等没有天然空格分词的文本
- WER:词错误率,适合英文等空格分词文本
- 归一化指标:去除标点、折叠空白、统一大小写后再计算,降低格式差异干扰
翻译任务不能只看字面差异,因为同一句话可能有多种正确译法。自动指标只是第一层筛选,语义诊断还需要 LLM judge 介入。
# 3.4 模型辅助诊断
评测完成后,可以再次调用模型,对"模型输出"和"标准答案"的差异进行结构化判断:
| 诊断字段 | 作用 |
|---|---|
| 是否可接受 | 判断差异是否影响语义正确性 |
| 严重程度 | 区分 minor / major / critical 等问题等级 |
| 问题类型 | 漏译、错译、数字错误、专名错误、幻觉、格式问题等 |
| 诊断原因 | 简短解释为什么这么判定 |
| 改进建议 | 指向模型、提示词、数据、接口或评分规则 |
模型复核不是最终真理,但它能把"分数为什么高/低"解释出来,让报告更接近真正关心的问题。
# 4. 什么才算"客观"的评测结果
平均错误率远远不够。一个可用的评测结果至少需要回答这些问题:
- 本轮跑了多少条样本?成功多少?失败多少?
- 平均 CER/WER 是多少?归一化后是否改善?
- 是否有空结果、协议失败、超时?
- 哪些样本是 bad case?参考答案和模型输出分别是什么?
- 错误是轻微格式差异,还是严重语义错误?
- 错误集中在哪类问题上?漏译、错译、数字、专名、幻觉,还是接口问题?
- 下一步应该改模型、改提示词、改数据,还是修接口?
下面是一份 ASR 报告的总体指标视图,展示了整体样本数、成功率、平均 CER、延迟、空结果与协议失败等指标:
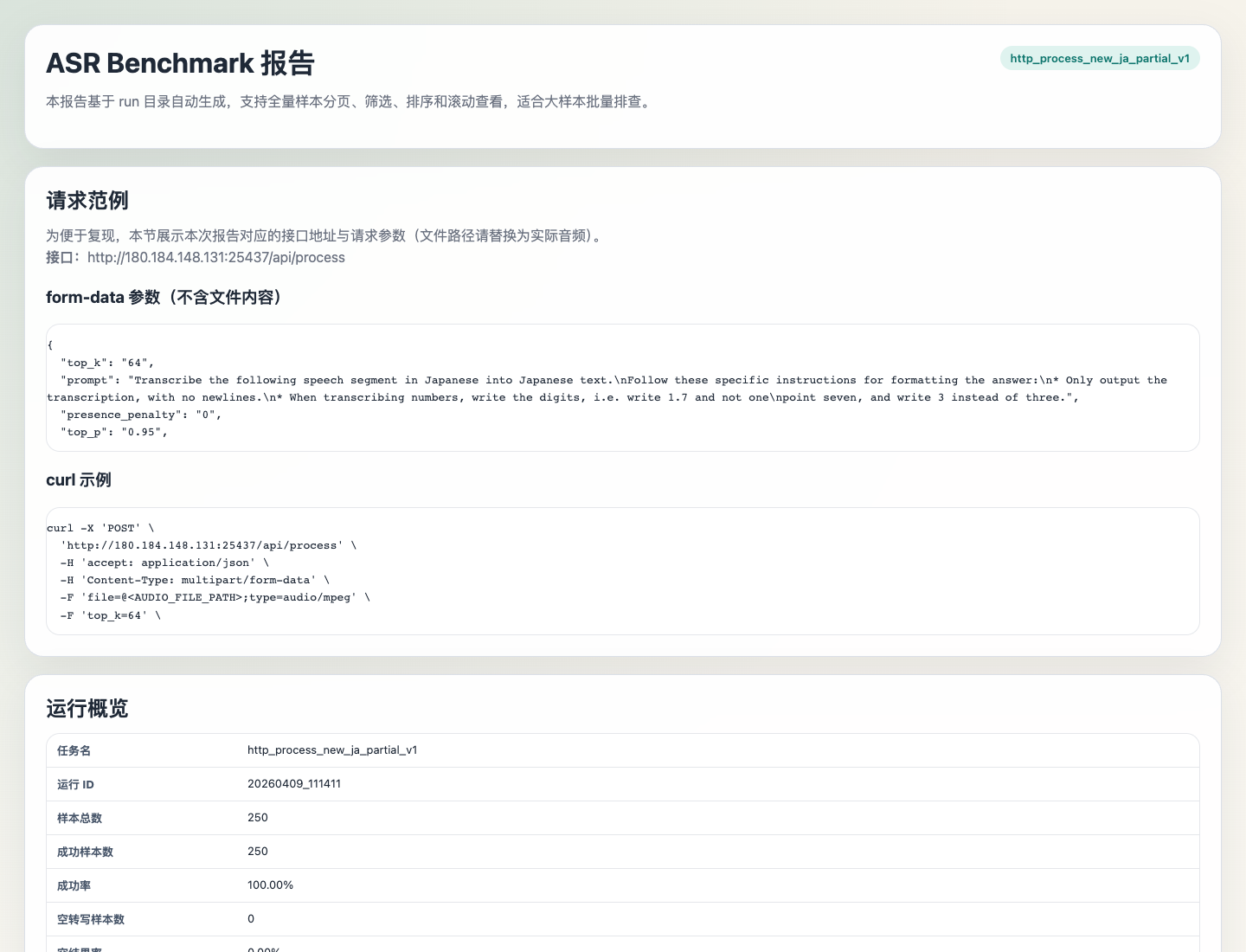
有了这种报告,讨论就不再停留在"这次感觉效果不太好",而可以具体到"哪批样本错误率高、哪些错误不可接受、问题是否来自模型能力"。
# 5. Bad case 才是改进的真正抓手
平均值只能说明整体趋势,真正推动改进的是 bad case。一个好的 bad case 展示应该包含:
- 样本 ID
- 标准答案
- 模型输出
- 原始错误率和归一化错误率
- 接口状态和错误信息
- 问题类型和严重程度
- 是否需要人工复核
下面是从同一份 ASR 报告里截取的 bad case 区域:
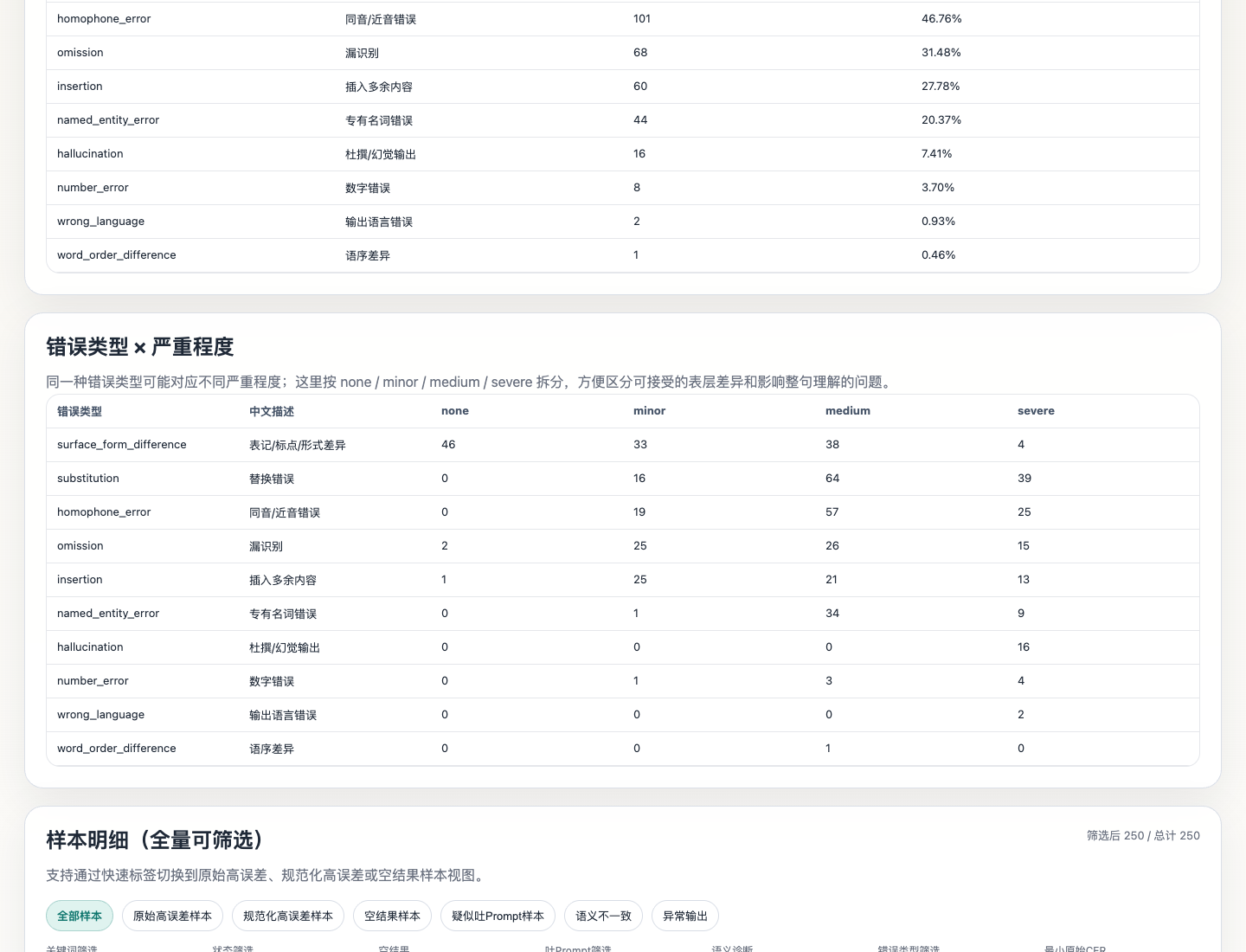
对于翻译任务,bad case 尤其重要。译文可能字面不同但语义正确,也可能字面接近但关键信息错了。只有把样本展开看,才能判断错误是否真的影响业务。
# 6. 实时翻译评测要再多看一层
实时翻译比普通 ASR 多了一层复杂度:它不只关心最终文本是否正确,还关心流式输出过程。
实时翻译报告除了准确性,还应该关注:
- 目标译文是否完整
- 是否有 token 级流式输出
- 是否生成 TTS 音频
- 源音频和 TTS 音频是否被保存
- 延迟是否稳定
- 分段输出是否影响最终语义
下面是实时翻译报告的总体视图,把接口调用状态、流式 token、音频产物和覆盖率放在同一个报告里:
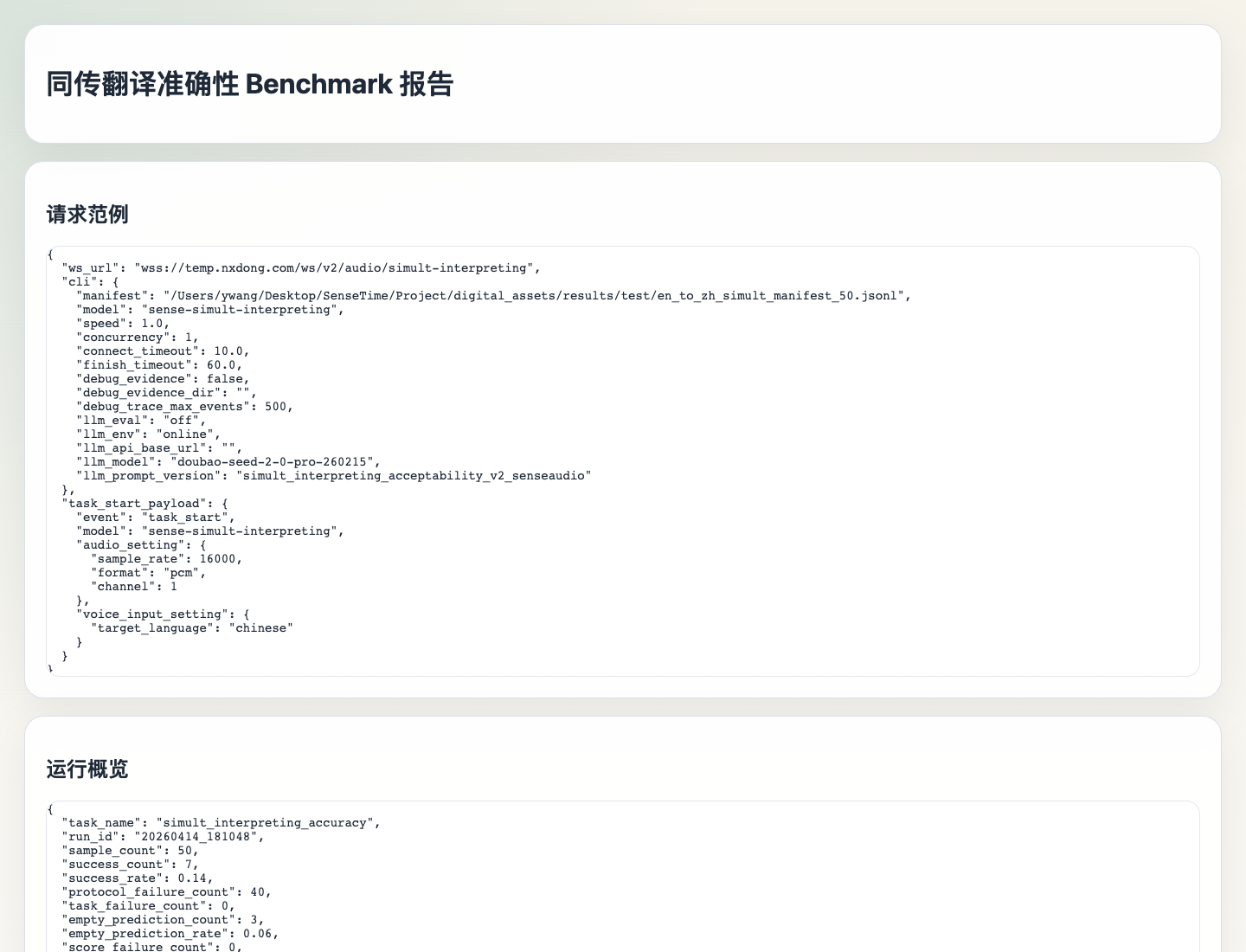
下面是同份报告的明细视图:
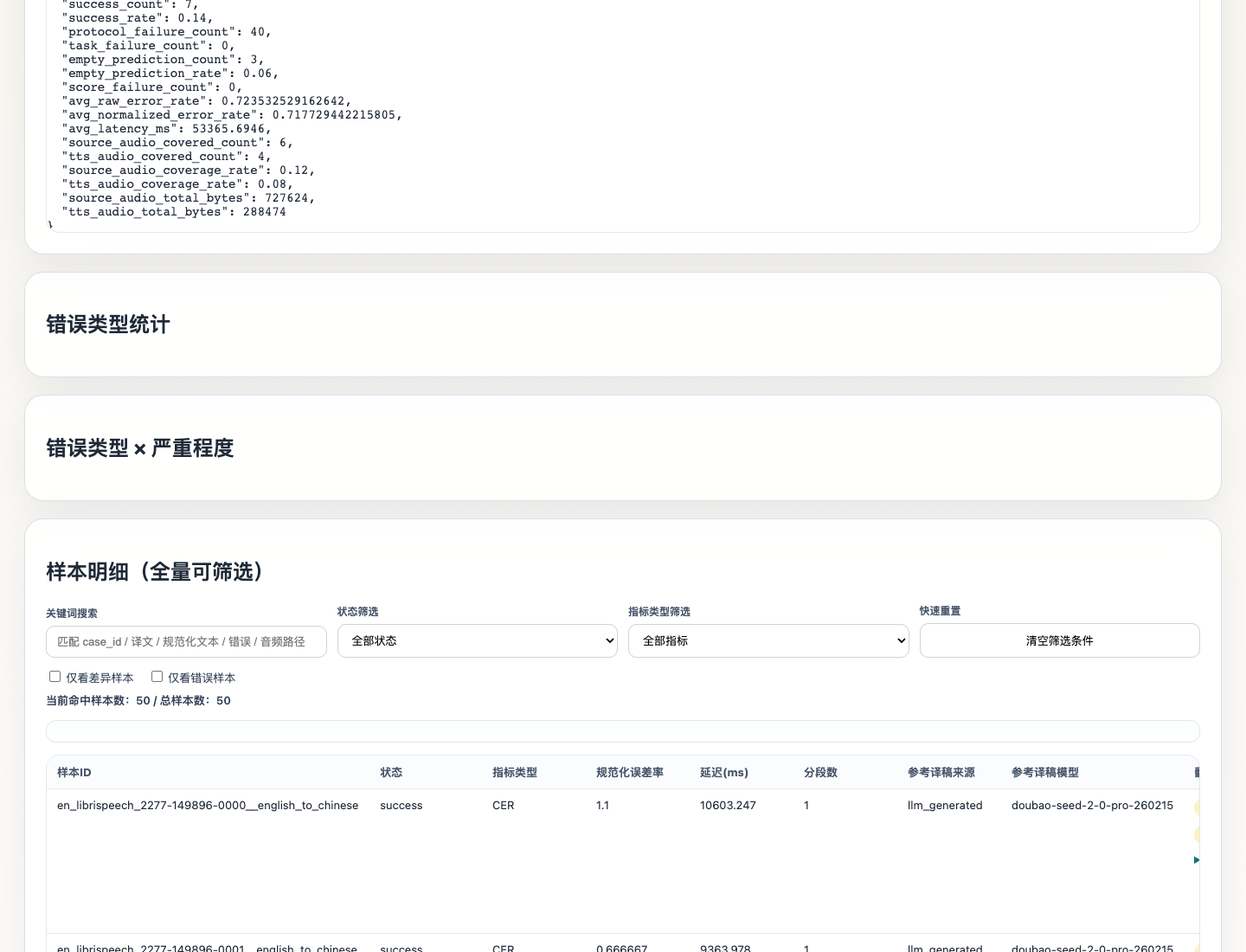
这说明了一个方向:未来评测不应只看最终译文,还要把流式过程、延迟、音频产物和终态稳定性纳入评测。
# 7. 这套方法能沉淀什么
值得沉淀的不是某一轮测试结论,而是通用方法:
| 可复用能力 | 价值 |
|---|---|
| 标准 manifest | 让样本可追踪、可迁移、可复跑 |
| 批量 benchmark runner | 避免人工逐条调用接口 |
| 多语言指标口径 | 避免英文、日文、中文混用同一套评分逻辑 |
| 模型辅助诊断 | 解释自动指标背后的语义问题 |
| HTML 报告模板 | 支持跨团队传播和复盘 |
| bad case 证据链 | 让每个结论都能回到原始样本和接口响应 |
这种方法可以迁移到摘要、改写、多模态理解、语音翻译、长文本理解等其他大模型能力评测。只要任务有标准答案或可定义参考答案,就可以把主观检查工程化。
# 8. 几个不能踩的坑
- 不要只跑几条样本就下结论
- 不要只看平均分,要看严重错误率和 bad case
- 不要把接口失败当成模型能力失败
- 不要把模型生成的参考答案直接当成最终标准
- 不要让 LLM judge 替代所有人工判断,要用抽检校准它
- 不要只产出 JSON,要产出能被团队理解的 HTML 报告
这套 ASR 与实时翻译准确性评测链路,本质上是在做一件事:把大模型能力从"主观体验"推进到"可测量、可解释、可复盘、可改进"。
- 01
- asr-translation-accuracy-benchmark06-10
- 02
- asr-translation-accuracy-benchmark06-10
- 03
- schoolbag-pilot-challenge06-09